Introduction
Automatic sound event detection (also called acoustic event detection) is one of the emerging topics of CASA research. Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene. Sound event detection can be utilized in a variety of applications, including context-based indexing and retrieval in multimedia databases, unobtrusive monitoring in health care, and surveillance. Furthermore, the detected events can be used as mid-level-representation in other research areas, e.g. audio context recognition, automatic tagging, and audio segmentation.
My topics for sound event detection include:
- Context-Dependent Detection [Heittola2013a]
- Event Priors [Mesaros2011]
- Detection in Multisource Environments [Heittola2011, Heittola2013a,Heittola2013b, Mesaros2015, Cakir2015a and Cakir2015b]
- Acoustic-Semantic Relationship of Labeled Sound Events [Mesaros2013b, Mesaros2013a]
The table and bar chart shows the progression of sound event detection performance evaluated with the same dataset (TUT CASA2009, later renamed as TUT-SED 2009).
| Name | Publication | Features |
Class models |
Detection method |
Context information |
Output format |
F-score (1 sec block) |
|---|---|---|---|---|---|---|---|
| Mesaros2010 | publications#Mesaros2010_EUSIPCO;Mesaros2010 | MFCC | 3-state HMM | Viterbi decoding | context-independent | monophonic | 8.4 |
| Heittola2013a_mono | publications#Heittola2013_EURASIP;Heittola2013a | MFCC | 3-state HMM | Viterbi decoding | context-dependent | monophonic | 14.6 |
| Heittola2013a_poly | publications#Heittola2013_EURASIP;Heittola2013a | MFCC | 3-state HMM | Multiple Viterbi | context-dependent | polyphonic | 19.5 |
| Heittola2011 | publications#Heittola2011_CHIME;Heittola2011 | MFCC | 3-state HMM | NMF | context-dependent | polyphonic | 37.0 |
| Heittola2013b | publications#Heittola2013_ICASSP;Heittola2013b | MFCC | 3-state HMM | NMF + stream selection | context-dependent | polyphonic | 45.0 |
| Mesaros2015 | publications#Mesaros2015_ICASSP;Mesaros2015 | MFCC or Mel band energy | no explicit models | Coupled NMF | context-dependent | polyphonic | 58.0 |
| Cakir2015a | publications#Cakir2015_IJCNN;Cakir2015a | Mel band energy | no explicit models | DNN | context-independent | polyphonic | 60.0 |
| Cakir2017 | publications#Cakir2017_TASLP;Cakir2017 | Mel band energy | no explicit models | CRNN | context-independent | polyphonic | 69.3 |
Demos
Demos requires the Flash player. Open the demos by clicking the image on the left.
Detection Results Visualization
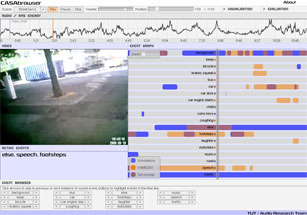
There is a visualization tool available to see our research results in action. In this tool, one can listen to the audio, while following the detection results along with annotations and corresponding video. Inside visualizer, one can select results presented in different papers [Heittola2013b, Heittola2013a, Heittola2011, Mesaros2011, Mesaros2010] and compare them to ground truth annotations.
Analysis on sound event labels using their co-occurrence
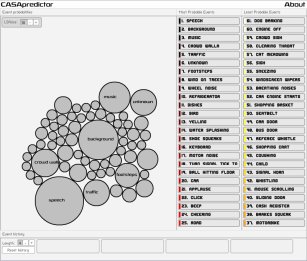
This is a visualization tool to demonstrate the sound event co-occurance model presented in [Mesaros2011]. In this tool, one can input sound event history and see predictions of upcoming sound events based on the history.
Acoustic-Semantic Relationship of Labeled Sound Events
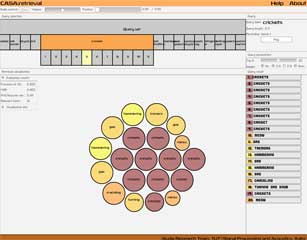
This demonstration illustrates the tradeoff between the two sides - search based only on semantic similarity, search based only on acoustic similarity, or using their weighted combination. This demo is based on results obtained in [Mesaros2013b].
Sound Events
Sound events are good descriptors for an auditory scene, as they help describing and understanding the human and social activities. A sound event is a label that people would use to describe a recognizable event in a region of the sound. Such a label usually allows people to understand the concept behind it and associate this event with other known events. Sound events can be used to represent a scene in a symbolic way, e.g. an auditory scene on a busy street contains events of passing cars, car horns and footsteps of people rushing. Auditory scenes can be described with different level descriptors to represent the general context (street) and the characteristic sound events (car, car horn, and footsteps).
Automatic Detection
In recent years, we have worked to extend the sound event detection task to a comprehensive set of event-annotated audio material from everyday environments. Most of the everyday auditory scenes are usually complex in sound events, having multiple overlapping sound events active at the same time, and this presents special challenged to the sound event detection process. In our research, we have addressed this problem and try to find ways to recognize and locate sound events in recordings with high degree of overlapping events.
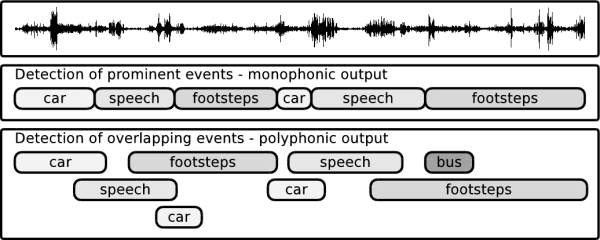
We have studied two alternative approaches for the sound event detection: in the first one, we find the most prominent event at each time instance, and in the second one we find a predefined number of overlapping events. The detection of the most prominent event will produce a monophonic event sequence as an output [Mesaros2010]. We call this approach as monophonic detection. The detection of overlapping events will produce a polyphonic event sequence as an output, and thus we call it as polyphonic detection [Heittola2011, Heittola2013a, Heittola2013b]. Examples of the outputs of these two approaches are shown in Figure 1.
Context-Dependent Detection
Automatic sound event detection systems are usually designed for specific tasks or specific environments. There are a number of challenges in extending the detection system to handle multiple environments and a large set of events. Event categories and variance within each category makes the automatic sound event recognition problem difficult even with well represented categories when having clean and undistorted signals. The challenge is the presence of certain sound events in multiple contexts (e.g. footsteps present in contexts like street, hallway, beach) calling for rules in modeling of the contexts. Some events are context specific (e.g. keyboard sounds present in the office context) and their variability is lower, as they always appear in similar conditions.
We have proposed a context-dependent approach to the sound event detection [Heittola2013a] to overcome these challenges. The approach is composed of two stages: automatic context recognition stage and sound event detection stage. In the first stage, audio context of the tested signal is recognized. Based on the recognized context, a context-specific set of sound event classes is selected for the sound event detection stage. The event detection stage also uses context-dependent acoustic models and count-based event priors. In the detection stage, each sound event class is represented by a Hidden Markov Model trained using Mel frequency cepstral coefficients (MFCC) extracted from the training material recorded in the specified context.
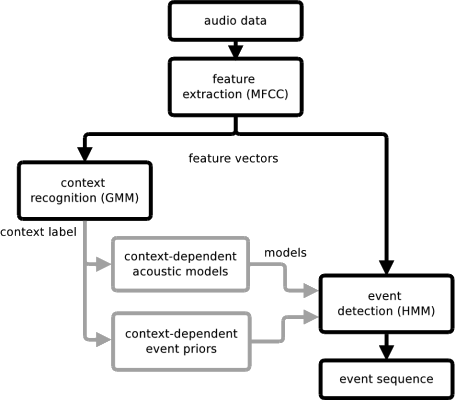
Event priors
In addition to the acoustic features and classification schemes, we have studied different methods to include prior knowledge of the events to the detection process. Acoustically homogeneous segments for the environment classification can be defined using frame level n-grams, where n-grams are used to model the prior probabilities of frames based on previously observed ones. However, in a complex acoustic environment with many overlapping events, the number of possible combinations is too high to be able to define such acoustically homogeneous segments and for modeling transitions between them.
A method of modeling overlapping event priors has been addressed in Mesaros2011, by using a probabilistic latent semantic analysis (PLSA) to calculate priors and learn associations between sound events. Co-occurrence of events is represented as the degree of their overlapping in a fixed length segment of polyphonic audio. In the training stage, PLSA is used to learn the relationships between individual events. In detection, the PLSA model continuously adjusts the probabilities of events according to the history of events detected so far. The event probabilities provided by the model are integrated into a sound event detection system that outputs a monophonic sequence of events.
The context-recognition stage proposed in Heittola2013a solved the associations of the sound events by splitting the event set into subsets according to the context. Furthermore, the count-based priors estimated from training material are used to provide probability distributions for the sound events inside each context.
Multisource Environments
We have proposed two approaches for a sound event detection in natural multisource environments which are able to detect multiple overlapping sound events. The first one is utilizing monophonic recording (mixture signal) as such, and in the detection stage multiple restricted Viterbi passes are used to capture overlapping events [Heittola2013a]. The second one is utilizing a unsupervised sound source separation as a preprocessing step to minimize the interference of overlapping events and detection stage is applied individually for separated streams [Heittola2011].
Unsupervised Sound Source Separation
In [Heittola2011], we proposed a sound event detection system for natural multisource environments, using a sound source separation as a front-end. The system is able to recognize and temporally locate overlapping sound events in recordings belonging to various audio contexts. The audio is preprocessed using non-negative matrix factorization and separated into four individual signals. Each sound event class is represented by a Hidden Markov Model trained using mel frequency cepstral coefficients extracted from the audio. Each separated signal is used individually for feature extraction and then segmentation and classification of sound events using the Viterbi algorithm. The sound source separation allows detection of a maximum of four overlapping events.
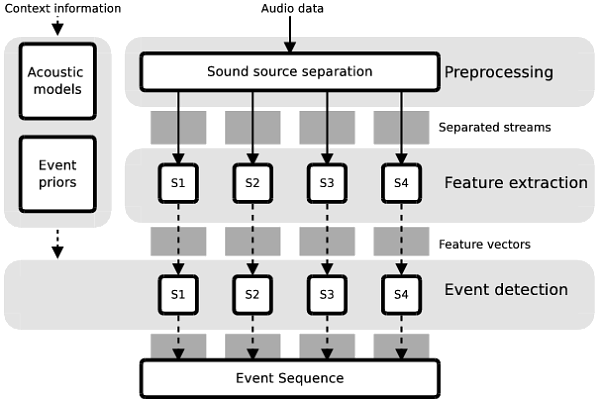
In the evaluations, sound source separation was found to substantially increase the sound detection accuracy compared to a system ([Mesaros2010]) able to output a single sequence of events. In addition to this, the proposed system produces a conceptually accurate symbolic representation of the environment by detecting overlapping events.
Supervised Model Training for Overlapping Sound Events
When the unsupervised sound source separation is used to minimize the interference of overlapping events in the sound event detection system, the supervised model training becomes problematic as there is no knowledge about which separated stream contains the targeted sound source. In [Heittola2013b], we proposed two iterative approaches based on EM algorithm to select the most likely stream to contain the target sound: one by selecting always the most likely stream and another one by gradually eliminating the most unlikely streams from the training. The approaches were evaluated with a database containing recordings from various contexts, against the baseline system [Heittola2011] trained without applying stream selection. Both proposed approaches were found to give a reasonable increase of 8 percentage units in the detection accuracy.
Acoustic-Semantic Relationship
A common problem of freely annotated or user contributed audio databases is the high variability of the labels, related to homonyms, synonyms, plurals, etc. Automatically re-labeling audio data based on audio similarity could offer a solution to this problem. In [Mesaros2013a], we studied the relationship between audio and labels in a sound event database, by evaluating semantic similarity of labels of acoustically similar sound event instances. The assumption behind the study was that acoustically similar events are annotated with semantically similar labels. Indeed, for 43% of the tested data, there was at least one in ten acoustically nearest neighbors having a synonym as label, while the closest related term is on average one level higher or lower in the semantic hierarchy.
In [Mesaros2013b], we proposed a method for combining audio similarity and semantic similarity into a single similarity measure for query-by-example retrieval. The integrated similarity measure is used to retrieve sound events that are similar in content to the given query and have labels containing similar words. Through the semantic component, the method is able to handle variability in labels of sound events. Through the acoustic component, the method retrieves acoustically similar examples. On a test database of over 3000 sound event examples, the proposed method obtained a better retrieval performance than audio-based retrieval, and returned results closer acoustically to the query than a label-based retrieval.