Introduction
Context recognition can be defined as the process of automatically determining the context around a device. Information about the context will enable wearable devices to provide better service to users' needs, e.g., by adjusting the mode of operation accordingly. Compared to image or video sensing, audio has certain distinctive characteristics. Audio captures information from all directions and is relatively robust to sensor position and orientation, which allows sensing without troubling the user. Audio can provide a rich set of information which can relate to location, activity, people, or what is being spoken. The acoustic ambiance and background noise characterizes a physical location, such as inside a car, restaurant, or office.
Methods
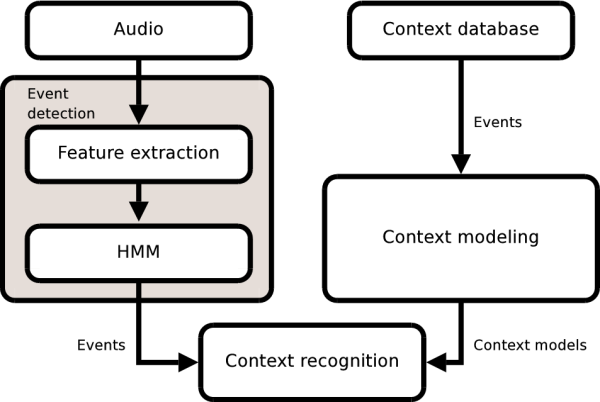
We have proposed a method based on representing each audio context using a histogram of sound events which are detected using a supervised classifier [Heittola2010]. In the training stage, each context is modeled with a histogram estimated from annotated training data. In the testing stage, individual sound events in the unknown recording are detected and a histogram of the sound event occurrences is built. Context recognition is performed by computing the cosine distance between this histogram and event histograms of each context from the training database. Compared to the more conventional context recognition system using only overall properties of the audio in the recognition, the proposed approach performed equally well. When combining these two context recognition approaches, recognition rate increases. This suggests that the proposed approach is providing complementary information about the context compared to the conventional approach.