Introduction
Understanding the timbre of musical instruments or drums are an important issue for automatic music transcription, music information retrieval and computational auditory scene analysis. In particular, recent worldwide popularization of online music distribution services and portable digital music players makes musical instrument recognition even more important.
In our research, we have focused on realistic multi-instrumental polyphonic audio. In polyphonic mixtures consisting of multiple instruments, the interference of simultaneously occurring sounds is likely to limit the recognition performance. The interference can be reduced by first separating the mixture into signals consisting of individual sound sources. In addition to the analysis of mixtures of sounds, sound source separation has applications in audio manipulation and object-based coding.
Sound Source Separation
Sound source separation techniques are used to separate instruments or drums from the polyphonic mixture signal and doing the recognition or transcription to these separated signals instead of the mixiture. Non-negative matrix factorization (NMF) techniques have become widely used in audio analysis and source separation. NMF is used presented the signal as a sum of components, each having a fixed spectrum and time-varying gain. The main benefit of this techniques is the ability to decompose a complex audio signal automatically into objects which have a meaningful interpretation. In the case of music signals, the resulting objects can correspond to individual pitches of each instrument, for example. Such a representation makes the analysis of complex signals significantly easier.
A shortcoming of the basic spectrogram decompositions is that each pitch of each instrument has to be represented with a unique basis functions. This requires a large amount of basis functions, making the separation and classification difficult.
Source-filter model
We have proposed ([Klapuri2010, Heittola2009]) a novel approach to musical instrument recognition in polyphonic audio signals by using a source-filter model and an augmented non-negative matrix factorization algorithm for sound separation. The mixture signal is decomposed into a sum of spectral bases modeled as a product of excitations and filters. The excitations are restricted to harmonic spectra and their fundamental frequencies are estimated in advance using a multipitch estimator, whereas the filters are restricted to have smooth frequency responses by modeling them as a sum of elementary functions on the Mel-frequency scale. The pitch and timbre information are used in organizing individual notes into sound sources.
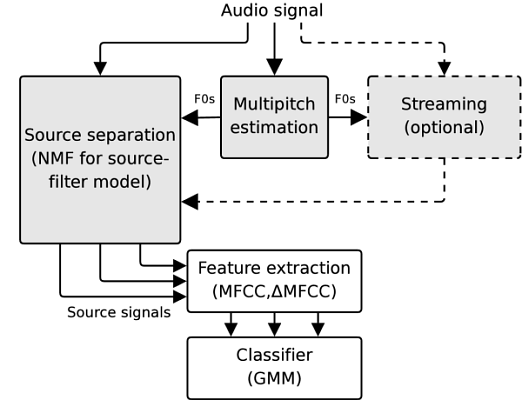
In the recognition, Mel-frequency cepstral coefficients are used to represent the coarse shape of the power spectrum of sound sources and Gaussian mixture models are used to model instrument-conditional densities of the extracted features. The system overview is shown in figure on the right-hand side.
Recently, the source-filter model has been found to produce very useful results in automatic music transcription and separation of musical instruments.
Interpolating State Model
State models are widely used in modeling, automatic recognition, and synthesis of audio signals since they allow modeling nonstationary sounds. Hidden Markov model (HMM) with continuous state emission functions is the most commonly used model in automatic speech recognition, since it provides a good framework for modeling the adverse acoustic characteristics of natural speech, simultaneously with high-level language modeling.
A major advantage of HMMs is also that the parameters can be efficiently estimating using training data. A drawback in HMMs is that each state produces observations which are independent from each other, whereas natural sounds sources have a strong correlation in time. This limitation is usually circumvented by using delta and acceleration features which model the temporal evolution of the signal.
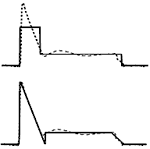
We have proposed [Virtanen2009] an interpolating extension to hidden Markov models (HMMs), which allows more accurate modeling of natural sounds sources. The model is able to produce observations from distributions which are interpolated between discrete HMM states. The model uses Gaussian mixture state emission densities, and the interpolation is implemented by introducing interpolating states in which the mixture weights, means, and variances are interpolated from the discrete HMM state densities. Figure on the right-hand side shows an example of interpolated state parameters for a single Gaussian. With an equal number of model parameters, the modeling error of the proposed model is significantly smaller. We also introduced an algorithm extended from the Baum-Welch algorithm for estimating the parameters of the interpolating model. The model was evaluated in automatic instrument recognition task, where it produced systematically better recognition accuracy than a baseline HMM recognition algorithm.