Introduction
Humans can easily segregate and recognize one sound source from an acoustic mixture, such as a certain voice from a busy background including other people talking and music. Machine listening systems try to achieve this perceptual feature using, for example, sound source recognition techniques.
My research is focusing on environmental audio, audio recordings made in the real auditory scene. More specifically, the main focus of the research is two-fold: analysis and synthesis of auditory scene. The analysis research is related to Computational Auditory Scene Analysis (CASA). CASA aims to separate and recognize mixtures of sound sources present in the auditory scene in a similar manner to humans. The synthesis side of the research aims to reproduce the mixture of sound sources while mimicking the characteristics of real auditory scenes.
Topics
Automatic sound event detection
Automatic sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene. Sound event detection can be utilized in a variety of applications, including context-based indexing and retrieval in multimedia databases, unobtrusive monitoring in health care, and surveillance. More
Automatic audio context recognition
Context recognition can be defined as the process of automatically determining the context around a device. Information about the context will enable wearable devices to provide better service to users' needs, e.g., by adjusting the mode of operation accordingly. More
Auditory scene synthesis
Auditory scene synthesis aims to create a new arbitrary long and representative audio ambiance for a location by using a small amount of audio recorded at the exact location. By adding this audio ambiance for the specific location in virtual location-exploration services (e.g. Google Street view) would enhance the user experience, giving the service a more 'real' feeling. More
Musical instrument recognition
Understanding the timbre of musical instruments or drums are an important issue for automatic music transcription, music information retrieval and computational auditory scene analysis. More
Demos
Open the demos by clicking the image on the left. Some of these demos requires the Flash player.
Sound Event Detection Results Visualization
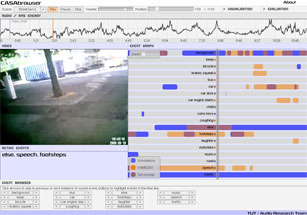
There is a visualization tool available to see our research results in action. In this tool, one can listen to the audio, while following the detection results along with annotations and corresponding video. Inside visualizer, one can select results presented in different papers [Heittola2013b, Heittola2013a, Heittola2011, Mesaros2011, Mesaros2010] and compare them to ground truth annotations.
Analysis on Sound Event Labels Using Their Co-occurrence
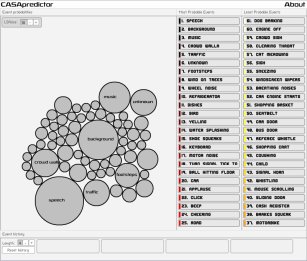
This is a visualization tool to demonstrate the sound event co-occurrence model presented in [Mesaros2011]. In this tool, one can input sound event history and see predictions of upcoming sound events based on the history.
Acoustic-Semantic Relationship of Labeled Sound Events
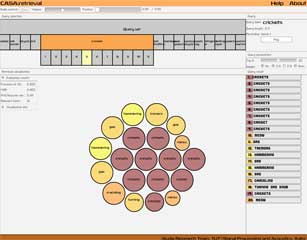
This demonstration illustrates the trade-off between the two sides - search based only on semantic similarity, search based only on acoustic similarity, or using their weighted combination. This demo is based on results obtained in [Mesaros2013b].
Continuous Noise Monitoring with Noise Source Recognition
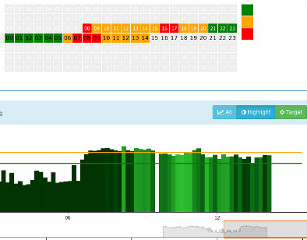
This demo illustrates how information from continuous noise monitoring with noise source recognition can be utilized and presented to users. This demo is based on results obtained in [Maijala2018].
Audio Textures
Here are demo samples created using method proposed in [Heittola2014]. Open the sample page by clicking the image on the left.